
Authenticated Web Archives: WACZ Files


In this article, you will learn more about what a web archive in the WACZ format is, how it is structured and authenticated, as well as how it can be used.
The Web Archive Collection Zipped (WACZ) is a file format specification for web archives created and used by Webrecorder. Within a compressed .wacz file you will find all of the data and documents required to re-create or replay web pages as they were captured at a certain point in time.
Such web archives provide tools for archivists and researchers against the issue of link rot. By capturing high-fidelity, replayable copies of webpages, we can preserve important technical, historic, and even legal context.
💡 WARC Files
The original type of files incorporated as an ISO standard in 2009 were called WARC files. WARC files can contain large amounts of data including images, video files, HTML, page styling, and more. These files were slow and unreliable to load and display in a web browser because they lacked indexes and other metadata that allow the browser to quickly download and display only the relevant pieces of data a user might want to view. With WARC files, the browser had to read and process all of the data contained in the file before it could load and display it. Using the WACZ file format (which incorporate WARC files) means that you are able to preview the photos and text on a page, before you would have to download, say, a large video file that was also a part of that captured web page.
WACZ files can include several WARC files, verification information such as signatures, as well as an index file that helps whichever tool (such as a web browser) that is going to display data locate and load only the data they need. The WACZ is a compressed file format which means that it takes up less space and bandwidth to read and transfer, while still making it possible to find and view the parts of the file that you want to preview.
Creating WACZ Files
WACZ files can be created either using an automated cloud-based tool that can be configured with URLs (and other options such as how many links deep you can crawl) or using a Chrome extension on your local device. Using either method, you’re able to capture web page(s) and information about those pages to make it easy to index and display. These files are stored in a set of pages called a collection. Learn more about creating pages in this post on Webrecorder Tools: Manual Crawl vs Browsertrix.
Viewing WACZ Files
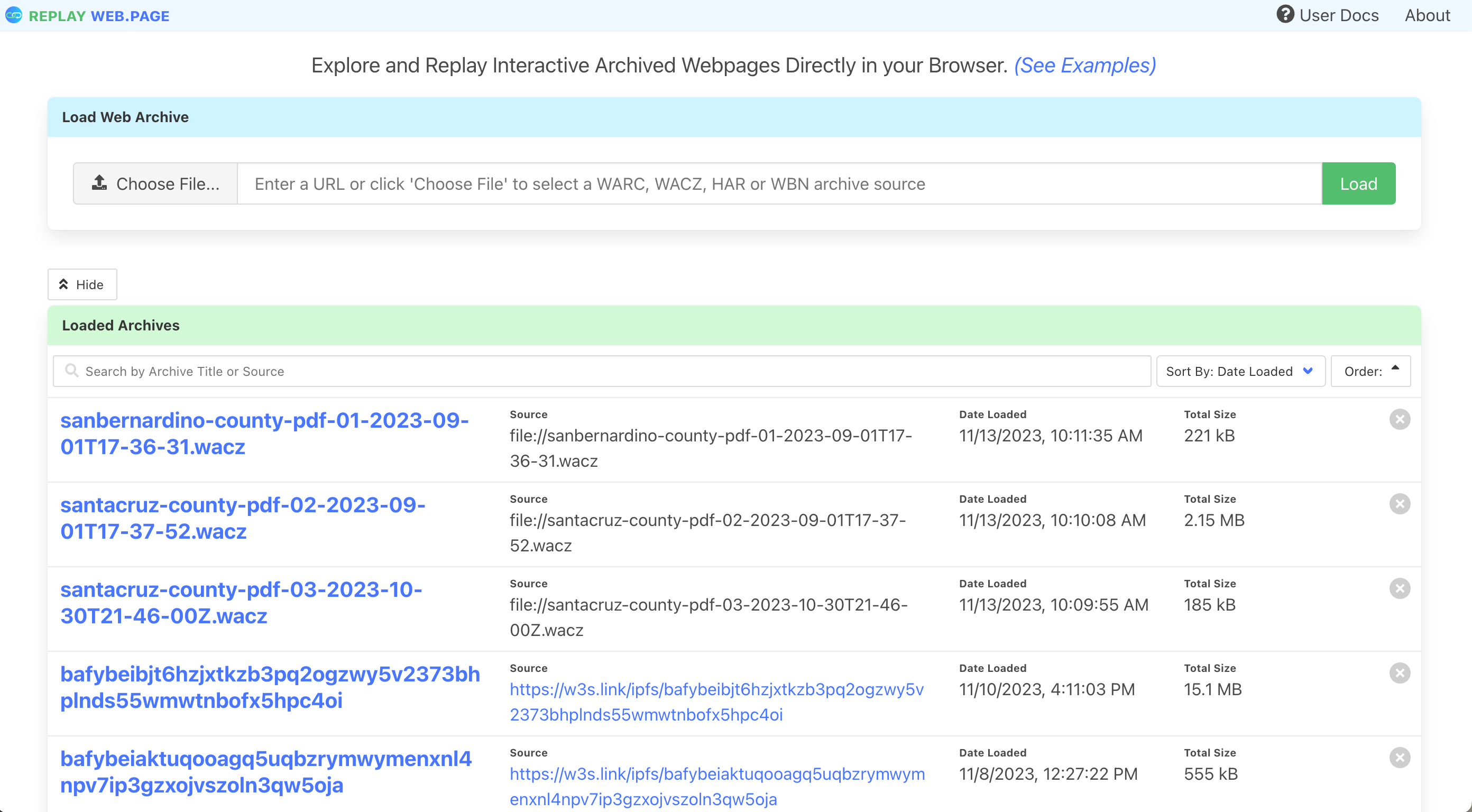
You can easily view and create views of .wacz files using the online webreplay tool, and by creating embedded views within another website. You can also download the webreplay app, and when you double click on any .wacz file on your computer, they will be opened automatically in the app.
Opening with the same Webrecorder tool you used to create them.
Online ReplayWeb.page Tool: https://replayweb.page/
Download ReplayWeb.page: https://replayweb.page/docs/loading_offline#replaywebpage-as-standalone-desktop-electron-app
Example Embedded Images: https://replayweb.page/docs/embedding
Example Web view: https://lab1.starling.hypha.coop/lab/embed/
Example 2: https://webrecorder.net/embed-demo-1.html
Example 3: https://webrecorder.net/embed-demo-2.html
Any type of website media (be it websites, social media posts, or video content) can be included in a .wacz file to be preserved and displayed by opening it in WebReplay.
WACZ File Structure
The .wacz file format makes it possible to capture all the pieces of content on a webpage to enable you to recreate, and even republish, a webpage as it was at a particular snapshot in time. If you change a .wacz file extension to a .zip extension, and you unzip a the file, inside you will see three directories and two .json files.
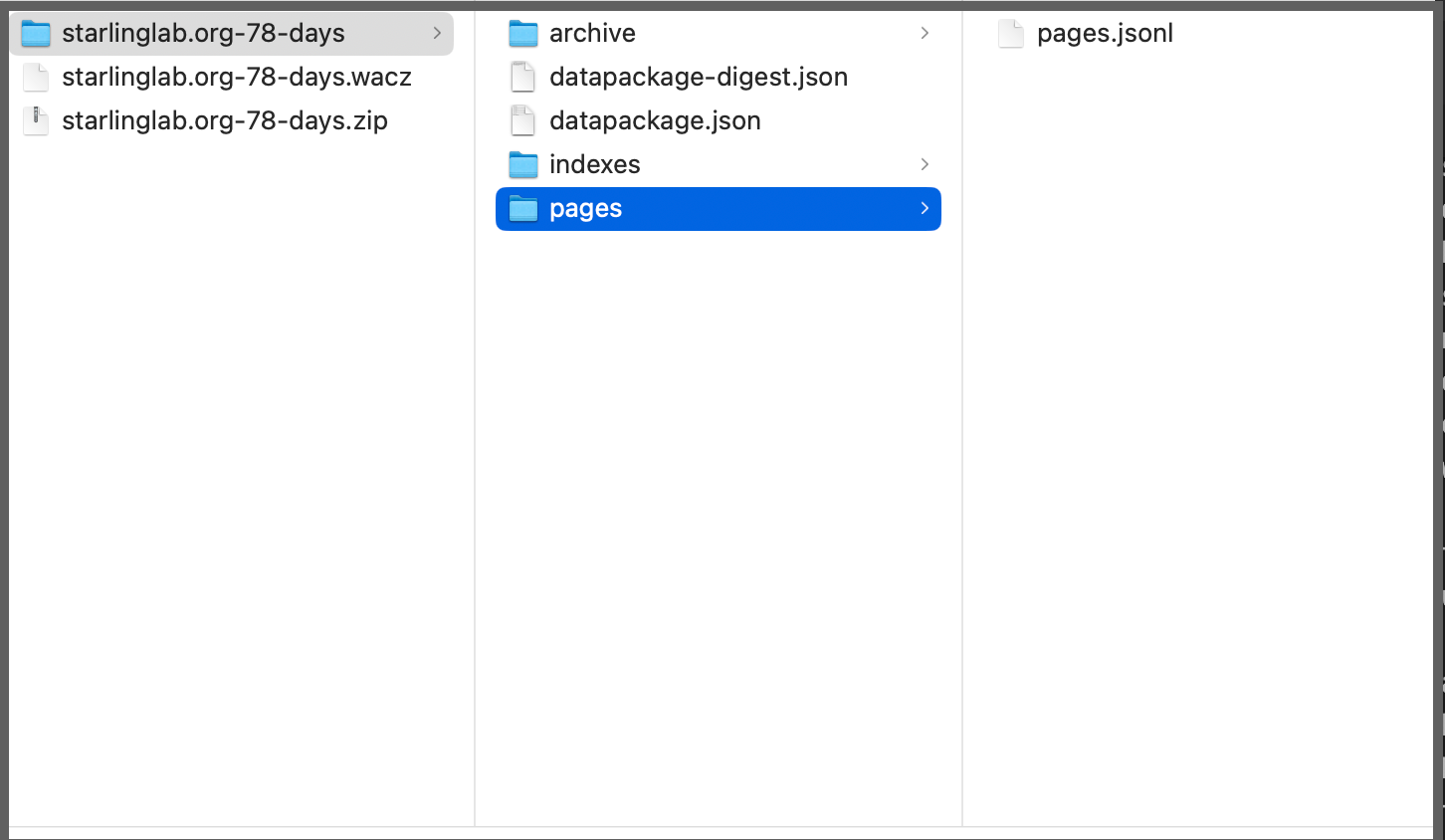
Inside the archive directory, you will find .warc files that contain the websites Inside the archive directory, you will find .warc files that contain the websites and other media scraped during a web recording.
The indexes directory contains files with a summary of where to find each piece of data for the web pages in the collection, as well as information about the interactions (such as clickable links or other options when a user interacts with a webpage).
The pages directory contains a file called pages.jsonl which is a set of JOSN files that contains key information for each individual page or ‘page object’ such as the url, timestamp, a title, and all the text for each page.
These files make it easy for web browsers to find and display pieces of a web page archive, without having to download and process the entire set of data and assets.
Each web archive requires that there is a datapackage.json file in the root of the WACZ archive that contains the filepath to all the other relevant pages, as well as a cryptographic hash of the data from that page. It also has the version of WACZ used to make this archive, and other information about the WACZ archive creation that can be used by the app when rendering the display.
In the datapackage-digest.json file you can see information about the authentication and preservation of the files. A cryptographic signature created from the datapackage.json file effectively gives you a fingerprint to identify that set of data (and a way to tell if that data was changed in any way).
WACZ Authentication and Preservation
One important aspect of website capture, preservation, and sharing is the authenticating of the date, time, and identity of the individual or entity that is capturing and storing that media. This authentication is done in a couple different ways.
The Starling Integrity Pipeline is an automated process for collecting, authenticating, and archiving files. It is a combination of Starling Lab’s integrity preprocessor which ingests and prepares different types of files (including files scraped with our instance of the automated Browsertrix web crawler), as well as the integrity backend that can be configured to authenticate and preserve files in distributed storage and on various blockchains.
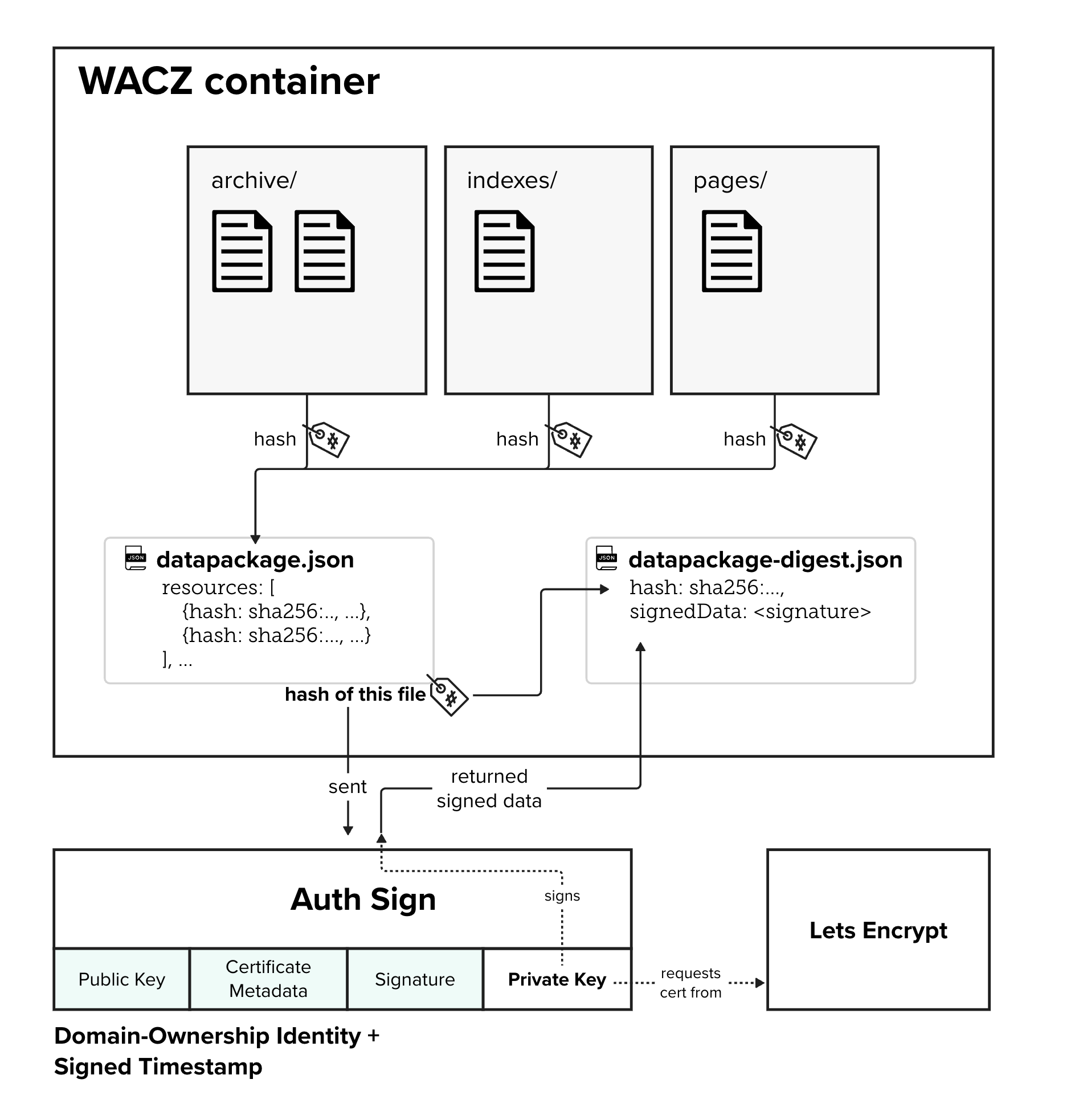
When Web archives are created and put into the Starling Integrity server, they are signed by both Browsertrix and signed again as a part of the Starling Integrity Pipeline. This signature validates that the entity doing the signing (either the Browsertrix application or Starling Lab) is in fact who they claim to be by using the X.509 SSL certificate used to verify domains.
Resources
Tool for viewing .wacz files: replayweb.page
Webrecorder Blog post on Web Archiving
Spec for Web Archive Collection Zipped
Embedding WACZ FIles
For troubleshooting and issues contact the Webrecorder team directly
 | A guest post by
|